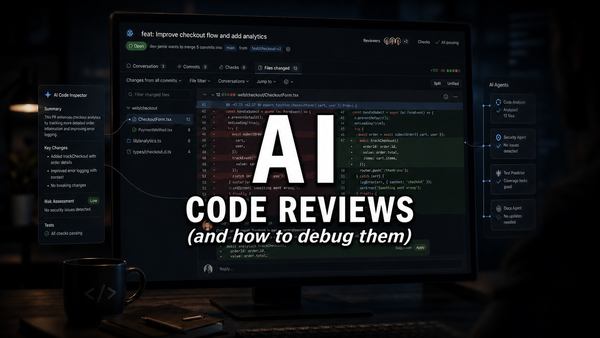
The “Human-in-the-Loop” Checklist:
Verifying AI-Generated Code
AI has made it dangerously easy to produce code that looks good at a glance. That’s not really the problem. The problem is that a lot of that code also looks good after the first review, after the first test run, and sometimes even after it lands in production.
That’s where the real work starts.
If you’ve been reviewing AI-assisted pull requests, you already know this feeling. The diff looks clean. The code compiles. The tests pass. And then, once you spend a little more time with it, you notice the naming doesn’t quite match the repo, the structure feels unnatural, or the implementation solves the obvious version of the problem instead of the real one. AI can generate a lot of code very quickly. What it still can’t do is understand your team, your architecture, or the operational scars that shaped the codebase in the first place.
What I look for first
When I review AI-generated code, I start with the same questions every time.
Does this actually solve the right problem? AI is usually fine at boilerplate and predictable patterns, but it’s much weaker when the code depends on company-specific logic, hidden constraints, or tribal knowledge that never made it into the prompt.
Does it fit the codebase? This is where the AI-isms show up. The naming is technically acceptable but slightly off. The abstraction is tidy in a way that no one on the team would naturally write. The comments feel generic. The structure is polished, but not familiar.
And most importantly: is it safe? That’s where I think a lot of teams need to be more deliberate. AI tools can be surprisingly careless around security boundaries. They may introduce unnecessary dependencies, unsafe shortcuts, or patterns that look convenient but would never survive a serious review if they touched auth, secrets, user input, or permissions.
Testing is where things get real
One of the best habits I’ve found is to make the AI help prove its own code.
If it writes the implementation, I want it to write the tests too. That’s where the gaps usually show up. A model can produce a happy-path implementation quickly, but tests force it to confront edge cases, failure modes, and assumptions it quietly made along the way.
That means looking for the stuff that breaks real systems:
- null or empty inputs.
- timeouts and retries.
- malformed data.
- permission failures.
- race conditions.
- rollback paths.
- the sort of bug that only shows up after a deployment when everybody is already trying to go home.
If the tests don’t make the behavior obvious, the code isn’t ready yet.
Custom agents as review partners
This is where I think things are going next.
Instead of relying on a generic AI assistant, teams can build custom agents that act more like specialized review partners. Their job isn’t to replace the reviewer. Their job is to compare a PR against the best examples already in the repository and call out where the new code drifts.
That’s a much more useful pattern.
A good review agent can look for naming consistency, architecture mismatches, missing tests, suspicious abstractions, and security patterns that don’t line up with the rest of the system. It can compare a change against accepted examples in the codebase and help answer a question that matters a lot more than “is this code valid?” — namely, “does this belong here?”
That’s also why I think AI tools are becoming useful in the opposite direction too: they’re starting to detect when code looks like it was written by another model. Not perfectly, and not in a way I’d treat as gospel, but often well enough to raise a flag when something feels synthetic or too generic. That doesn’t mean we obsess over whether code was written by a person or a model. It means we pay closer attention when the shape of the code looks off.
Why the review process matters
At the end of the day, I want a review process that does three things well.
It checks correctness.
It checks security.
It checks whether the code actually fits the system.
That last part is the one people underestimate. A lot of code is not bad because it is broken. It is bad because it doesn’t belong. It doesn’t match the style, the architecture, or the operational reality of the team that has to maintain it.
That’s why I still think human judgment matters more than ever. AI can generate the first draft, and custom agents can help compare and triage it, but someone still has to make the call about whether the change is actually right. The goal isn’t to move faster by skipping review. The goal is to move faster because the review process is better.
AI made code generation cheap. Verification is now the scarce skill.









{kind=link}